Функция ошибки нейронной сети. Алгоритм обратного распространения ошибки (Back propagation algorithm). Обратное распространение ошибки и произведение матриц
Алгоритм обратного распространения ошибки является одним из методов обучения многослойных нейронных сетей прямого распространения, называемых также многослойными персептронами. Многослойные персептроны успешно применяются для решения многих сложных задач.
Обучение алгоритмом обратного распространения ошибки предполагает два прохода по всем слоям сети: прямого и обратного. При прямом проходе входной вектор подается на входной слой нейронной сети, после чего распространяется по сети от слоя к слою. В результате генерируется набор выходных сигналов, который и является фактической реакцией сети на данный входной образ. Во время прямого прохода все синаптические веса сети фиксированы. Во время обратного прохода все синаптические веса настраиваются в соответствии с правилом коррекции ошибок, а именно: фактический выход сети вычитается из желаемого, в результате чего формируется сигнал ошибки. Этот сигнал впоследствии распространяется по сети в направлении, обратном направлению синаптических связей. Отсюда и название – алгоритм обратного распространения ошибки . Синаптические веса настраиваются с целью максимального приближения выходного сигнала сети к желаемому.
Рассмотрим работу алгоритма подробней. Допустим необходимо обучить следующую нейронную сеть, применив алгоритм обратного распространения ошибки:

На приведенном рисунке использованы следующие условные обозначения:
В качестве активационной функции в многослойных персептронах, как правило, используется сигмоидальная активационная функция, в частности логистическая:

где – параметр наклона сигмоидальной функции. Изменяя этот параметр, можно построить функции с различной крутизной. Оговоримся, что для всех последующих рассуждений будет использоваться именно логистическая функция активации, представленная только, что формулой выше.

Сигмоид сужает диапазон изменения так, что значение лежит между нулем и единицей. Многослойные нейронные сети обладают большей представляющей мощностью, чем однослойные, только в случае присутствия нелинейности. Сжимающая функция обеспечивает требуемую нелинейность. В действительности имеется множество функций, которые могли бы быть использованы. Для алгоритма обратного распространения ошибки требуется лишь, чтобы функция была всюду дифференцируема. Сигмоид удовлетворяет этому требованию. Его дополнительное преимущество состоит в автоматическом контроле усиления. Для слабых сигналов (т.е. когда близко к нулю) кривая вход-выход имеет сильный наклон, дающий большое усиление. Когда величина сигнала становится больше, усиление падает. Таким образом, большие сигналы воспринимаются сетью без насыщения, а слабые сигналы проходят по сети без чрезмерного ослабления.
Целью обучения сети алгоритмом обратного распространения ошибки является такая подстройка ее весов, чтобы приложение некоторого множества входов приводило к требуемому множеству выходов. Для краткости эти множества входов и выходов будут называться векторами. При обучении предполагается, что для каждого входного вектора существует парный ему целевой вектор, задающий требуемый выход. Вместе они называются обучающей парой. Сеть обучается на многих парах.
Следующий:
- Инициализировать синаптические веса маленькими случайными значениями.
- Выбрать очередную обучающую пару из обучающего множества; подать входной вектор на вход сети.
- Вычислить выход сети.
- Вычислить разность между выходом сети и требуемым выходом (целевым вектором обучающей пары).
- Подкорректировать веса сети для минимизации ошибки (как см. ниже).
- Повторять шаги с 2 по 5 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемого уровня.
Операции, выполняемые шагами 2 и 3, сходны с теми, которые выполняются при функционировании уже обученной сети, т.е. подается входной вектор и вычисляется получающийся выход. Вычисления выполняются послойно. На рис. 1 сначала вычисляются выходы нейронов слоя (слой входной, а значит никаких вычислений в нем не происходит), затем они используются в качестве входов слоя , вычисляются выходы нейронов слоя , которые и образуют выходной вектор сети . Шаги 2 и 3 образуют так называемый «проход вперед», так как сигнал распространяется по сети от входа к выходу.
Шаги 4 и 5 составляют «обратный проход», здесь вычисляемый сигнал ошибки распространяется обратно по сети и используется для подстройки весов.
Рассмотрим подробней 5 шаг – корректировка весов сети. Здесь следует выделить два нижеописанных случая.
Случай 1. Корректировка синаптических весов выходного слоя
Например, для модели нейронной сети на рис. 1, это будут веса имеющие следующие обозначения: и . Определимся, что индексом будем обозначать нейрон, из которого выходит синаптический вес, а – нейрон в который входит:

Введем величину , которая равна разности между требуемым и реальным выходами, умноженной на производную логистической функции активации (формулу логистической функции активации см. выше):

Тогда, веса выходного слоя после коррекции будут равны:
Приведем пример вычислений для синаптического веса :

Случай 2. Корректировка синаптических весов скрытого слоя
Для модели нейронной сети на рис. 1, это будут веса соответствующие слоям и . Определимся, что индексом будем обозначать нейрон из которого выходит синаптический вес, а – нейрон в который входит (обратите внимание на появление новой переменной ).
В первой части были рассмотрены: структура, топология, функции активации и обучающее множество. В этой части попробую объяснить как происходит обучение сверточной нейронной сети.
Обучение сверточной нейронной сети
На начальном этапе нейронная сеть является необученной (ненастроенной). В общем смысле под обучением понимают последовательное предъявление образа на вход нейросети, из обучающего набора, затем полученный ответ сравнивается с желаемым выходом, в нашем случае это 1 – образ представляет лицо, минус 1 – образ представляет фон (не лицо), полученная разница между ожидаемым ответом и полученным является результат функции ошибки (дельта ошибки). Затем эту дельту ошибки необходимо распространить на все связанные нейроны сети.Таким образом обучение нейронной сети сводится к минимизации функции ошибки, путем корректировки весовых коэффициентов синаптических связей между нейронами. Под функцией ошибки понимается разность между полученным ответом и желаемым. Например, на вход был подан образ лица, предположим, что выход нейросети был 0.73, а желаемый результат 1 (т.к. образ лица), получим, что ошибка сети является разницей, то есть 0.27. Затем веса выходного слоя нейронов корректируются в соответствии с ошибкой. Для нейронов выходного слоя известны их фактические и желаемые значения выходов. Поэтому настройка весов связей для таких нейронов является относительно простой. Однако для нейронов предыдущих слоев настройка не столь очевидна. Долгое время не было известно алгоритма распространения ошибки по скрытым слоям.
Алгоритм обратного распространения ошибки
Для обучения описанной нейронной сети был использован алгоритм обратного распространения ошибки (backpropagation). Этот метод обучения многослойной нейронной сети называется обобщенным дельта-правилом. Метод был предложен в 1986 г. Румельхартом, Макклеландом и Вильямсом. Это ознаменовало возрождение интереса к нейронным сетям, который стал угасать в начале 70-х годов. Данный алгоритм является первым и основным практически применимым для обучения многослойных нейронных сетей.Для выходного слоя корректировка весов интуитивна понятна, но для скрытых слоев долгое время не было известно алгоритма. Веса скрытого нейрона должны изменяться прямо пропорционально ошибке тех нейронов, с которыми данный нейрон связан. Вот почему обратное распространение этих ошибок через сеть позволяет корректно настраивать веса связей между всеми слоями. В этом случае величина функции ошибки уменьшается и сеть обучается.
Основные соотношения метода обратного распространения ошибки получены при следующих обозначениях:
Величина ошибки определяется по формуле 2.8 среднеквадратичная ошибка:

Неактивированное состояние каждого нейрона j для образа p записывается в виде взвешенной суммы по формуле 2.9:

Выход каждого нейрона j является значением активационной функции
Которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:

В качестве метода минимизации ошибки используется метод градиентного спуска, суть этого метода сводится к поиску минимума (или максимума) функции за счет движения вдоль вектора градиента. Для поиска минимума движение должно быть осуществляться в направлении антиградиента. Метод градиентного спуска в соответствии с рисунком 2.7.
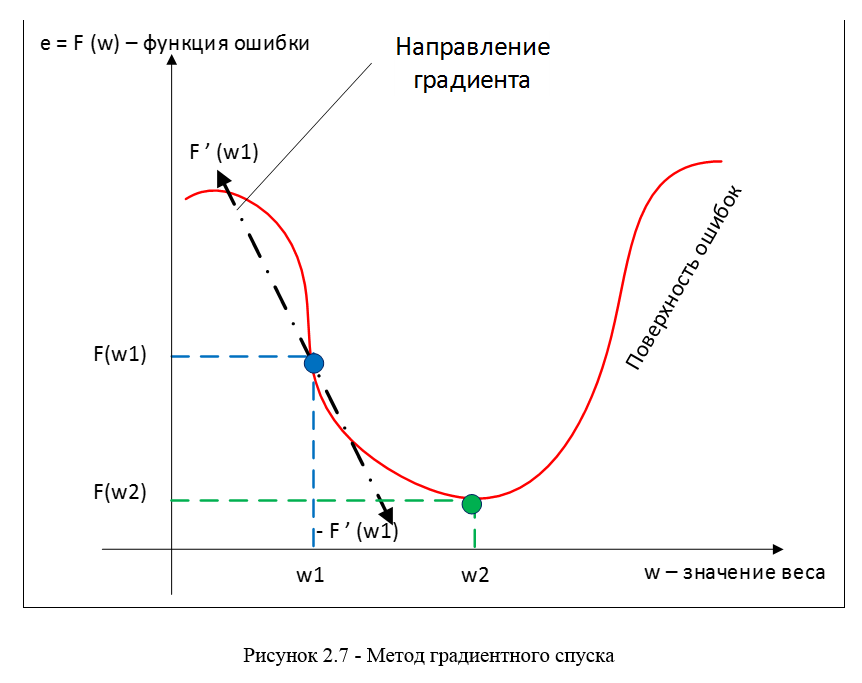
Градиент функции потери представляет из себя вектор частных производных, вычисляющийся по формуле 2.11:

Производную функции ошибки по конкретному образу можно записать по правилу цепочки, формула 2.12:

Ошибка нейрона обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y , то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
Ошибка δ для скрытого слоя рассчитывается по формуле 2.13:
Алгоритм распространения ошибки сводится к следующим этапам:
- прямое распространение сигнала по сети, вычисления состояния нейронов;
- вычисление значения ошибки δ для выходного слоя;
- обратное распространение: последовательно от конца к началу для всех скрытых слоев вычисляем δ по формуле 2.13;
- обновление весов сети на вычисленную ранее δ ошибки.

До этого момента были рассмотрены случаи распространения ошибки по слоям персептрона, то есть по выходному и скрытому, но помимо них, в сверточной нейросети имеются подвыборочный и сверточный.
Расчет ошибки на подвыборочном слое
Расчет ошибки на подвыборочном слое представляется в нескольких вариантах. Первый случай, когда подвыборочный слой находится перед полносвязным, тогда он имеет нейроны и связи такого же типа, как в полносвязном слое, соответственно вычисление δ ошибки ничем не отличается от вычисления δ скрытого слоя. Второй случай, когда подвыборочный слой находится перед сверточным, вычисление δ происходит путем обратной свертки. Для понимания обратно свертки, необходимо сперва понять обычную свертку и то, что скользящее окно по карте признаков (во время прямого распространения сигнала) можно интерпретировать, как обычный скрытый слой со связями между нейронами, но главное отличие - это то, что эти связи разделяемы, то есть одна связь с конкретным значением веса может быть у нескольких пар нейронов, а не только одной. Интерпретация операции свертки в привычном многослойном виде в соответствии с рисунком 2.8.
Рисунок 2.8 - Интерпретация операции свертки в многослойный вид, где связи с одинаковым цветом имеют один и тот же вес. Синим цветом обозначена подвыборочная карта, разноцветным – синаптическое ядро, оранжевым – получившаяся свертка
Теперь, когда операция свертки представлена в привычном многослойном виде, можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети. Соответственно имея вычисленные ранее дельты сверточного слоя можно вычислить дельты подвыборочного, в соответствии с рисунком 2.9.
Рисунок 2.9 - Вычисление δ подвыборочного слоя за счет δ сверточного слоя и ядра
Обратная свертка
– это тот же самый способ вычисления дельт, только немного хитрым способом, заключающийся в повороте ядра на 180 градусов и скользящем процессе сканирования сверточной карты дельт с измененными краевыми эффектами. Простыми словами, нам необходимо взять ядро сверточной карты (следующего за подвыборочным слоем) повернуть его на 180 градусов и сделать обычную свертку по вычисленным ранее дельтам сверточной карты, но так чтобы окно сканирования выходило за пределы карты. Результат операции обратной свертки в соответствии с рисунком 2.10, цикл прохода обратной свертки в соответствии с рисунком 2.11.
Рисунок 2.10 - Результат операции обратной свертки

Рисунок 2.11 - Повернутое ядро на 180 градусов сканирует сверточную карту
Расчет ошибки на сверточном слое
Обычно впередиидущий слой после сверточного это подвыборочный, соответственно наша задача вычислить дельты текущего слоя (сверточного) за счет знаний о дельтах подвыборочного слоя. На самом деле дельта ошибка не вычисляется, а копируется. При прямом распространении сигнала нейроны подвыборочного слоя формировались за счет неперекрывающегося окна сканирования по сверточному слою, в процессе которого выбирались нейроны с максимальным значением, при обратном распространении, мы возвращаем дельту ошибки тому ранее выбранному максимальному нейрону, остальные же получают нулевую дельту ошибки.Заключение
Представив операцию свертки в привычном многослойном виде (рисунок 2.8), можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети.Метод обратного распространения ошибки
Метод обратного распространения ошибки - метод обучения многослойного персептрона, один из вариантов обучения с учителем. Впервые метод был описан Полом Дж. Вербосом. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж. Е. Хинтоном и Рональдом Дж. Вильямсом. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.
Основная идея этого метода состоит в распространении сигналов ошибки от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности»), приложимый к более широкому классу систем, включая системы с запаздыванием, распределённые системы, и т.п.
Метод является модификацией классического метода градиентного спуска.
Алгоритм метода обратного распространения ошибки
Пусть у нас имеется многослойная сеть прямого распространения со случайными весовыми коэффициентами. Есть некоторое обучающее множество, состоящее из пар вход сети - желаемый выход. Через Y обозначим реальное выходное значение нашей сети, которое в начале практически случайно из-за случайности весовых коэффициентов.
Обучение состоит в том, чтобы подобрать весовые коэффициенты таким образом, чтобы минимизировать некоторую целевую функцию. В качестве целевой функции рассмотрим сумму квадратов ошибок сети на примерах из обучающего множества.
где реальный выход N-го выходного слоя сети для p-го нейрона на j-м обучающем примере, желаемый выход. То есть, минимизировав такой функционал, мы получим решение по методу наименьших квадратов.
Поскольку весовые коэффициенты в зависимость входят нелинейно, воспользуемся для нахождения минимума методом наискорейшего спуска. То есть на каждом шаге обучения будем изменять весовые коэффициенты по формуле

где весовой коэффициент j-го нейрона n-го слоя для связи с i-м нейроном (n-1)-го слоя.
Параметр называется параметром скорости обучения.
Таким образом, требуется определить частные производные целевой функции E по всем весовым коэффициентам сети. Согласно правилам дифференцирования сложной функции

где - выход, а - взвешенная сума входов j-го нейрона n-го слоя. Заметим, что, зная функцию активации, мы можем вычислить. Например, для сигмоида эта величина будет равняться

Третий сомножитель / есть ни что иное, как выход i-го нейрона (n-1)-го слоя, то есть

Частные производные целевой функции по весам нейронов выходного слоя теперь можно легко вычислить. Производя дифференцирование (1) по и учитывая (3) и (5) будем иметь

Введем обозначение

Тогда для нейронов выходного слоя

Для весовых коэффициентов нейронов внутренних слоев мы не можем сразу записать, чему равен первый сомножитель из (4), однако его можно представить следующим образом:
Заметим, что в этой формуле первые два сомножителя есть не что иное, как. Таким образом, с помощью (9) можно выражать величины для нейронов n-го слоя черездля нейронов (n+1)-го. Поскольку для последнего слоя легко вычисляется по (8), то можно с помощью рекурсивной формулы

получить значения для вех нейронов всех слоев.
Окончательно формулу (2) для модификации весовых коэффициентов можно записать в виде
Таким образом, полный алгоритм обучения нейронной сети с помощью алгоритма обратного распространения строиться следующим образом.
Присваиваем всем весовым коэффициентам сети случайные начальные значения. При этом сеть будет осуществлять какое-то случайное преобразование входных сигналов и значения целевой функции (1) будут велики.
Подать на вход сети один из входных векторов из обучающего множества. Вычислить выходные значения сети, запоминая при этом выходные значения каждого из нейронов.
Скорректировать веса сети:
Оценка работы сети
В тех случаях, когда удается оценить работу сети, обучение нейронных сетей можно представить как задачу оптимизации. Оценить - означает указать количественно, хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) - от всех её параметров. Простейший и самый распространенный пример оценки - сумма квадратов расстояний от выходных сигналов сети до их требуемых значений:
где - требуемое значение выходного сигнала.
Метод наименьших квадратов далеко не всегда является лучшим выбором оценки. Тщательное конструирование функции оценки позволяет на порядок повысить эффективность обучения сети, а также получать дополнительную информацию - «уровень уверенности» сети в даваемом ответе.
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага з, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска, то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Основную трудность при обучении нейронных сетей составляют как раз методы выхода из локальных минимумов: каждый раз выходя из локального минимума, снова ищется следующий локальный минимум тем же методом обратного распространения ошибки до тех пор, пока найти из него выход уже не удаётся.
Размер шага
Внимательный разбор доказательства сходимости показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведёт к бесконечному времени обучения. Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость. Эффективно увеличивать шаг до тех пор, пока не прекратится улучшение оценки в данном направлении антиградиента и уменьшать, если такого улучшения не происходит. П. Д. Вассерман описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня предложена разветвлённая технология оптимизации обучения.
Следует также отметить возможность переобучения сети, что является скорее результатом ошибочного проектирования её топологии. При слишком большом количестве нейронов теряется свойство сети обобщать информацию. Весь набор образов, предоставленных к обучению, будет выучен сетью, но любые другие образы, даже очень похожие, могут быть классифицированы неверно.
Среда разработки и причины ее выбора
Разработка приложения будет осуществляться на языке программирования C# с фреймворком.NETFramework4.0 в среде разработки MicrosoftVisualStudio 2010. Фрагменты кода, требующие массивных вычислений, разработаны на языке C++. MSVisualStudio 2010 включает в себя полный набор новых и улучшенных функций, упрощающих все этапы процесса разработки от проектирования до развертывания.
MicrosoftVisualStudio 2010 Ultimate - интегрированная среда инструментальных средств и серверная инфраструктура, упрощающая процесс разработки приложения в целом. Для создания бизнес-приложений используются эффективные, предсказуемые, настраиваемые процессы. Детальная аналитика повышает прозрачность и прослеживаемость всего жизненного цикла приложения. Как при создании новых решений, так и при доработке существующих, доступна разработка с помощью мощных инструментов создания прототипов, проектирования архитектуры и разработки, которые позволяют разрабатывать приложения для всевозможных платформ и технологий, таких как обработка данных в облаке и параллельная обработка данных. Расширенные возможности координирования совместной деятельности наряду с интегрированными инновационными инструментами тестирования и отладки обеспечат повышение производительности группы и создание высококачественных и недорогих решений.
Разработка приложений в MicrosoftVisualStudio2010 Ultimate на языке C# с фреймворком.NETFramework4.0 осуществляется с применением объектно-ориентированного программирования и визуального программирования.
Для обучения многослойной сети в 1986 г. Руммельхартом и Хинтоном (Rummelhart D.E., Hinton G.E., Williams R.J., 1986) был предложен алгоритм обратного распостранения ошибок (error back propagation). Многочисленные публикации о промышленных применениях многослойных сетей с этим алгоритмом обучения подтвердили его принципиальную работоспособность на практике.
В начале возникает резонный вопрос - а почему для обучения многослойного персептрона нельзя применить уже известное -правило Розенблатта (см. Лекцию 4)? Ответ состоит в том, что для применения метода Розенблатта необходимо знать не только текущие выходы нейронов y, но и требуемыеправильные значенияY . В случае многослойной сети эти правильные значения имеются только для нейроноввыходного слоя. Требуемые значения выходов для нейронов скрытых слоев неизвестны, что и ограничивает применение-правила.
Основная идея обратного распространения состоит в том, как получить оценку ошибки для нейронов скрытых слоев. Заметим, что известные ошибки, делаемые нейронами выходного слоя, возникают вследствиенеизвестных пока ошибок нейронов скрытых слоев. Чем больше значение синаптической связи между нейроном скрытого слоя и выходным нейроном, тем сильнее ошибка первого влияет на ошибку второго. Следовательно, оценку ошибки элементов скрытых слоев можно получить, как взвешенную сумму ошибок последующих слоев. При обучении информация распространяется от низших слоев иерархии к высшим, а оценки ошибок, делаемые сетью - в обратном напаравлении, что и отражено в названии метода.
Перейдем к подробному рассмотрению этого алгоритма. Для упрощения обозначений ограничимся ситуацией, когда сеть имеет только один скрытый слой. Матрицу весовых коэффициентов от входов к скрытому слою обозначим W, а матрицу весов, соединяющих скрытый и выходной слой - как V. Для индексов примем следующие обозначения: входы будем нумеровать только индексом i, элементы скрытого слоя - индексом j, а выходы, соответственно, индексом k.
Пусть сеть обучается на выборке (X,Y),=1..p. Активности нейронов будем обозначать малыми буквами y с соотвествующим индексом, а суммарные взвешенные входы нейронов - малыми буквами x.
Общая структура алгоритма аналогична рассмотренной в Лекции 4, с усложнением формул подстройки весов.
Таблица 6.1. Алгоритм обратного распространения ошибки.
|
Начальные значения весов всех нейронов всех слоев V(t=0) и W(t=0) полагаются случайными числами. |
|
|
Сети предъявляется входной образ X, в результате формируется выходной образ yY. При этом нейроны последовательно от слоя к слою функционируют по следующим формулам: скрытый слой выходной слой
Здесь f(x) - сигмоидальная функция, определяемая по формуле (6.1) |
|
|
Функционал квадратичной ошибки сети для данного входного образа имеет вид:
Данный функционал подлежит минимизации. Классический градиентный метод оптимизации состоит в итерационном уточнении аргумента согласно формуле:
Функция ошибки в явном виде не содержит зависимости от веса V jk , поэтому воспользуемся формулами неявного дифференцирования сложной функции:
Здесь учтено полезное свойство сигмоидальной функции f(x): ее производная выражается только через само значение функции, f’(x)=f(1-f). Таким образом, все необходимые величины для подстройки весов выходного слоя V получены. |
|
|
На этом шаге выполняется подстройка весов скрытого слоя. Градиентный метод по-прежнему дает:
Вычисления производных выполняются по тем же формулам, за исключением некоторого усложнения формулы для ошибки j .
При вычислении j здесь и был применен принцип обратного распространения ошибки: частные производные берутся только по переменнымпоследующего слоя. По полученным формулам модифицируются веса нейронов скрытого слоя. Если в нейронной сети имеется несколько скрытых слоев, процедура обратного распространения применяется последовательно для каждого из них, начиная со слоя, предшествующего выходному, и далее до слоя, следующего за входным. При этом формулы сохраняют свой вид с заменой элементов выходного слоя на элементы соотвествующего скрытого слоя. |
|
|
Шаги 1-3 повторяются для всех обучающих векторов. Обучение завершается по достижении малой полной ошибки или максимально допустимого числа итераций, как и в методе обучения Розенблатта. |





Как видно из описания шагов 2-3, обучение сводится к решению задачи оптимизации функционала ошибки градиентным методом. Вся “соль” обратного распространения ошибки состоит в том, что для ее оценки для нейронов скрытых слоев можно принять взвешенную сумму ошибок последующего слоя.
Параметр h имеет смысл темпа обучения и выбирается достаточно малым для сходимости метода. О сходимости необходимо сделать несколько дополнительных замечаний. Во-первых, практика показывает что сходимость метода обратного распространения весьма медленная. Невысокий тепм сходимости является “генетической болезнью” всех градиентных методов, так как локальное направление градиента отнюдь не совпадает с направлением к минимуму. Во-вторых, подстройка весов выполняется независимо для каждой пары образов обучающей выборки. При этом улучшение функционирования на некоторой заданной паре может, вообще говоря, приводить к ухудшению работы на предыдущих образах. В этом смысле, нет достоверных (кроме весьма обширной практики применения метода) гарантий сходимости.
Исследования показывают, что для представления произвольного функционального отображения, задаваемого обучающей выборкой, достаточно всего два слоя нейронов. Однако на практике, в случае сложных функций, использование более чем одного скрытого слоя может давать экономию полного числа нейронов.
В завершение лекции сделаем замечание относительно настройки порогов нейронов. Легко заметить, что порог нейрона может быть сделан эквивалентным дополнительному весу, соединенному с фиктивным входом, равным -1. Действительно, выбирая W 0 =, x 0 =-1 и начиная суммирование с нуля, можно рассматривать нейрон с нулевым порогом и одним дополнительным входом:

Дополнительные входы нейронов, соотвествующие порогам, изображены на Рис. 6.1 темными квадратиками. С учетом этого замечания, все изложенные в алгоритме обратного распространения формулы суммирования по входам начинаются с нулевого индекса.
Ошибки от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности »), приложимый к более широкому классу систем, включая системы с запаздыванием, распределённые системы , и т. п.
Для возможности применения метода обратного распространения ошибки передаточная функция нейронов должна быть дифференцируема . Метод является модификацией классического метода градиентного спуска .
Сигмоидальные функции активации
Наиболее часто в качестве функций активации используются следующие виды сигмоид :
Функция Ферми (экспоненциальная сигмоида):
Рациональная сигмоида:
Гиперболический тангенс:
,где s - выход сумматора нейрона, - произвольная константа.
Менее всего, сравнительно с другими сигмоидами, процессорного времени требует расчет рациональной сигмоиды. Для вычисления гиперболического тангенса требуется больше всего тактов работы процессора. Если же сравнивать с пороговыми функциями активации, то сигмоиды рассчитываются очень медленно. Если после суммирования в пороговой функции сразу можно начинать сравнение с определенной величиной (порогом), то в случае сигмоидальной функции активации нужно рассчитать сигмоид (затратить время в лучшем случае на три операции: взятие модуля, сложение и деление), и только потом сравнивать с пороговой величиной (например, нулём). Если считать, что все простейшие операции рассчитываются процессором за примерно одинаковое время, то работа сигмоидальной функции активации после произведённого суммирования (которое займёт одинаковое время) будет медленнее пороговой функции активации как 1:4.
Функция оценки работы сети
В тех случаях, когда удается оценить работу сети, обучение нейронных сетей можно представить как задачу оптимизации. Оценить - означает указать количественно, хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) - от всех её параметров. Простейший и самый распространенный пример оценки - сумма квадратов расстояний от выходных сигналов сети до их требуемых значений:
,где - требуемое значение выходного сигнала.
Описание алгоритма

Архитектура многослойного перцептрона
Алгоритм обратного распространения ошибки применяется для многослойного перцептрона . У сети есть множество входов , множество выходов Outputs и множество внутренних узлов. Перенумеруем все узлы (включая входы и выходы) числами от 1 до N (сквозная нумерация, вне зависимости от топологии слоёв). Обозначим через вес, стоящий на ребре, соединяющем i-й и j-й узлы, а через - выход i-го узла. Если нам известен обучающий пример (правильные ответы сети , ), то функция ошибки, полученная по методу наименьших квадратов , выглядит так:
Как модифицировать веса? Мы будем реализовывать стохастический градиентный спуск , то есть будем подправлять веса после каждого обучающего примера и, таким образом, «двигаться» в многомерном пространстве весов. Чтобы «добраться» до минимума ошибки, нам нужно «двигаться» в сторону, противоположную градиенту , то есть, на основании каждой группы правильных ответов, добавлять к каждому весу
,где - множитель, задающий скорость «движения».
Производная считается следующим образом. Пусть сначала , то есть интересующий нас вес входит в нейрон последнего уровня. Сначала отметим, что влияет на выход сети только как часть суммы , где сумма берется по входам j-го узла. Поэтому
Аналогично, влияет на общую ошибку только в рамках выхода j-го узла (напоминаем, что это выход всей сети). Поэтому
Если же j-й узел - не на последнем уровне, то у него есть выходы; обозначим их через Children(j). В этом случае
, .Ну а - это в точности аналогичная поправка, но вычисленная для узла следующего уровня будем обозначать ее через - от она отличается отсутствием множителя . Поскольку мы научились вычислять поправку для узлов последнего уровня и выражать поправку для узла более низкого уровня через поправки более высокого, можно уже писать алгоритм. Именно из-за этой особенности вычисления поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:
- для узла последнего уровня
- для внутреннего узла сети
- для всех узлов
Получающийся алгоритм представлен ниже. На вход алгоритму, кроме указанных параметров, нужно также подавать в каком-нибудь формате структуру сети. На практике очень хорошие результаты показывают сети достаточно простой структуры, состоящие из двух уровней нейронов - скрытого уровня (hidden units) и нейронов-выходов (output units); каждый вход сети соединен со всеми скрытыми нейронами, а результат работы каждого скрытого нейрона подается на вход каждому из нейронов-выходов. В таком случае достаточно подавать на вход количество нейронов скрытого уровня.
Алгоритм
Алгоритм: BackPropagation
где - коэффициент инерциальнности для сглаживания резких скачков при перемещении по поверхности целевой функции
Математическая интерпретация обучения нейронной сети
На каждой итерации алгоритма обратного распространения весовые коэффициенты нейронной сети модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется четырьмя специфическими ограничениями, выделяющими обучение нейросетей из общих задач оптимизации: астрономическое число параметров, необходимость высокого параллелизма при обучении, многокритериальность решаемых задач, необходимость найти достаточно широкую область, в которой значения всех минимизируемых функций близки к минимальным. В остальном проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы («как правило») связана с тем, что на самом деле нам неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки. Минимизация оценки - сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС - от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов.
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска , то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Основную трудность при обучении нейронных сетей составляют как раз методы выхода из локальных минимумов: каждый раз выходя из локального минимума снова ищется следующий локальный минимум тем же методом обратного распространения ошибки до тех пор, пока найти из него выход уже не удаётся.
Размер шага
Внимательный разбор доказательства сходимости показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведёт к бесконечному времени обучения. Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость. Эффективно увеличивать шаг до тех пор, пока не прекратится улучшение оценки в данном направлении антиградиента и уменьшать, если такого улучшения не происходит. П. Д. Вассерман описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня предложена разветвлённая технология оптимизации обучения.
Следует также отметить возможность переобучения сети, что является скорее результатом ошибочного проектирования её топологии. При слишком большом количестве нейронов теряется свойство сети обобщать информацию. Весь набор образов, предоставленных к обучению, будет выучен сетью, но любые другие образы, даже очень похожие, могут быть классифицированы неверно.
См. также
- Алгоритм скоростного градиента
Литература
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика . - М .: «Мир», 1992.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. - М.: Издательский дом Вильямс, 2008, 1103 с.
Ссылки
- Копосов А. И., Щербаков И. Б., Кисленко Н. А., Кисленко О. П., Варивода Ю. В. и др. . - М .: ВНИИГАЗ, 1995.